DATA PROTECTION TRENDS, NEWS & BACKUP TIPS
Database Recovery Best Practices for Critical Systems
Critical databases, such as case management systems, student record databases, and other vital data stores, need special care to ensure you can quickly bounce back from any failure or data loss.
Even a minimal amount of data loss or downtime can result in significant business impact.
Below are key best practices for protecting these databases. Perform frequent transaction log backups, regularly test restores, and use tools that enable point-in-time recovery. Following these practices helps SMB and mid market IT teams safeguard vital data and maintain business continuity.
1) Frequent Transaction Log Backups (Minimize Data Loss)
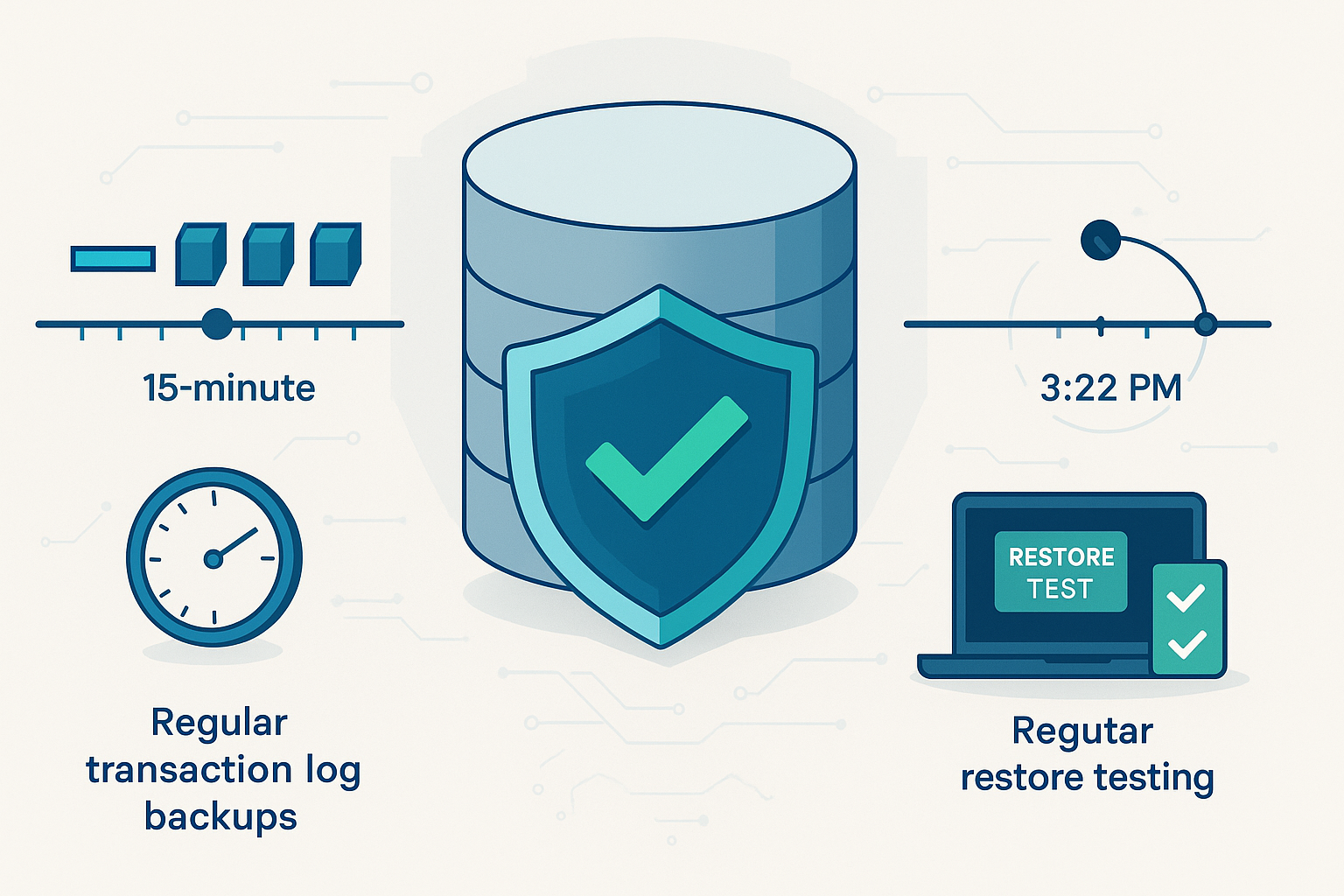
For databases that support transaction logs or continuous write-ahead logs, frequent log backups are a cornerstone of a good recovery strategy. Regular log backups capture all changes since the last full or incremental backup, which helps minimize data loss in a failure.
Align the frequency with your Recovery Point Objective (RPO). If you cannot afford to lose more than 15 minutes of work, schedule log backups at least every 15 minutes.
Increasing backup frequency shrinks the window of potential data loss and helps prevent logs from growing uncontrollably. In systems that use a full recovery model, logs do not clear without backups and can fill a disk. Frequent log backups protect your data and keep systems running efficiently.
Fold log backups into a broader schedule. Start with a full backup as your baseline, then add periodic fulls, differentials, and frequent log backups. In a recovery, restore the most recent full, then the latest differential, and finally replay all subsequent logs to recover up to the moment just before an incident.
2) Regular Restore Testing (Trust but Verify Your Backups)
Having backups is not enough. You must regularly test restoring those backups.
The condition of any backup is unknown until a restore is attempted. A backup that reports as successful can still be corrupted or incomplete, which you discover only during a crisis.
Schedule periodic recovery drills for your critical databases. Simulate a full restore in a test environment and verify that the database comes back online with intact, usable data.
Cover multiple scenarios. Practice restoring a few tables or records, and also perform a complete database recovery on a clean server. This ensures the team is confident and the process is documented.
Regular testing helps you catch problems early and confirm that you can meet your Recovery Time Objective (RTO). In critical environments, test major restores at least annually or semi-annually. Document the steps and make sure more than one team member can execute them, so you are not reliant on a single expert in an emergency.
3) Point-in-Time Recovery Tools (Enable “Time Travel” for Your Data)
When an error or data corruption occurs, point-in-time recovery (PITR) lets you rewind the database to just before the incident. PITR restores the database to an exact moment rather than only to the last full backup.
This is especially valuable for fast-changing systems like case management or student records. If someone makes a mistake at 3:23 PM, you can restore the database as it was at 3:22 PM. You undo the error without losing the entire day’s work.
To use PITR, make sure your backup solution or database platform supports granular recovery with transaction logs or continuous snapshots. Most enterprise-grade databases and many backup services provide this capability. Take advantage of it so you are not limited to fixed restore points.
Key benefits of point-in-time recovery:
- Minimized data loss. Restore to moments before an incident and preserve more work.
- Recovery from human error. Quickly revert to a safe time after accidental deletes or changes.
- Confidence under pressure. Knowing you can turn back time helps teams respond calmly and effectively.
Remember that frequent log backups or a continuous archive of write-ahead logs fuel PITR. Include a point-in-time scenario in your restore drills. For example, practice restoring last Tuesday’s database to 10:45 AM and confirm the data is correct.
Next Steps
Caring for critical databases means preparing not just for if something goes wrong, but when. Frequent transaction log backups, rigorous restore testing, and point-in-time recovery tools create a safety net that protects your most important data.
These practices apply whether you are safeguarding SQL Server, Oracle, PostgreSQL, or other platforms. The principles of data protection are universal.
Not sure if your backup strategy covers all the bases? Schedule a free backup assessment with our team. We will review your database backup and recovery setup, identify gaps such as missing log backups or untested restores, and help you strengthen the plan.